Científicos de la iniciativa europea Venomics han recogido muestras de 120 especies venenosas para analizar sus toxinas, con las que se podrán desarrollar nuevos medicamentos. Cuando finalice este proyecto sus promotores esperan obtener más 20.000 secuencias, lo que constituirá la mayor base de datos de secuencias de estas sustancias nocivas con potencial sanador.
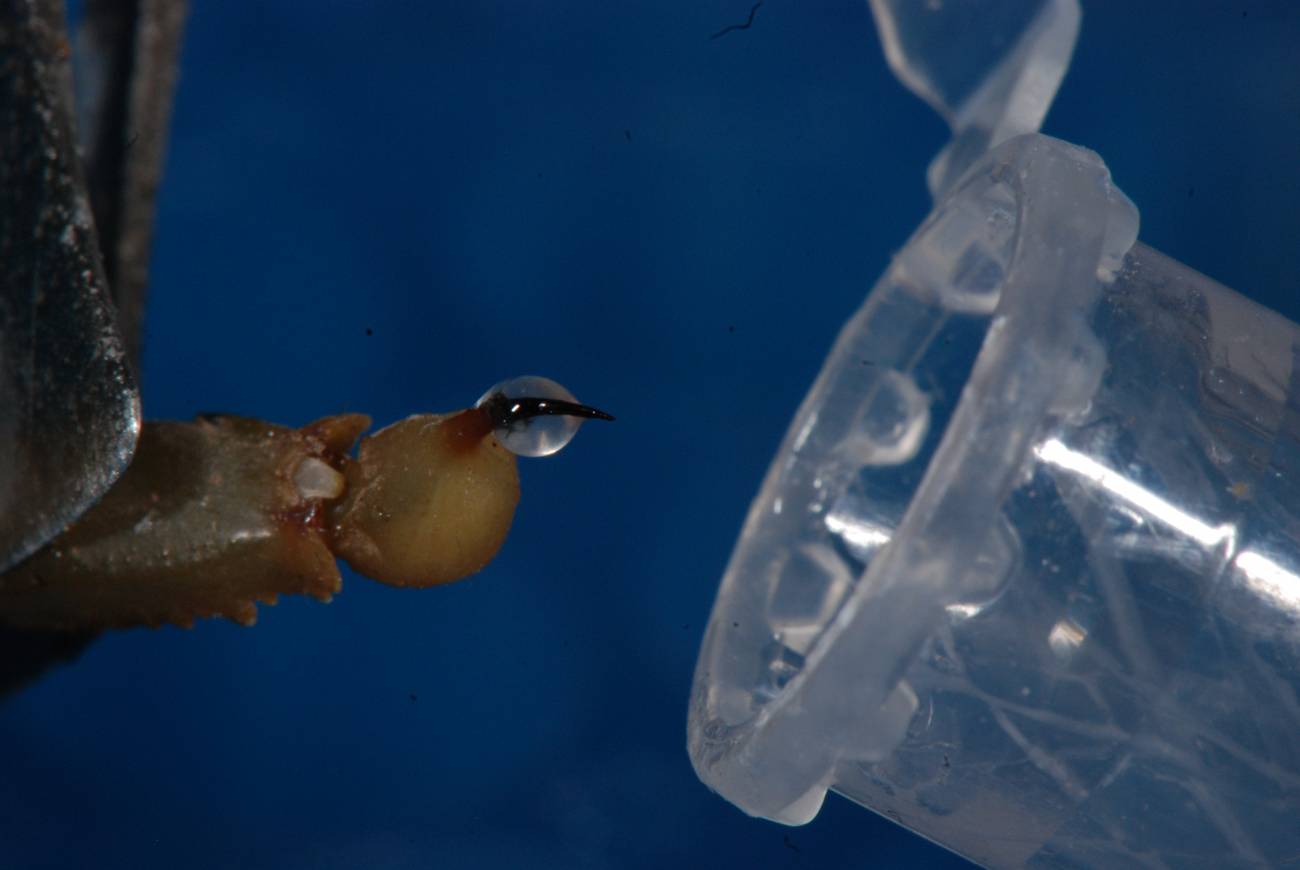
Científicos de la iniciativa europea Venomics han recogido muestras de 120 especies venenosas para analizar sus toxinas, con las que se podrán desarrollar nuevos medicamentos. Cuando finalice este proyecto se esperan obtener más 20.000 secuencias, lo que constituirá la mayor base de datos de secuencias de estas sustancias nocivas con potencial sanador.
Este martes se han presentado en Lisboa los primeros resultados del proyecto Venomics, una iniciativa europea compuesta por ocho socios privados y públicos que, desde 2011, tienen como objetivo explorar y explotar los venenos como un recurso para desarrollar medicamentos innovadores.
“Es el proyecto más grande hasta el momento en este campo en todo el mundo, explorando la capacidad de los venenos para generar fármacos a una escala que nunca antes se había producido, con más de 200 venenos investigados”, resalta el doctor Nicolas Gilles, coordinador general del proyecto.
El equipo de científicos ha viajado a distintas zonas del mundo (especialmente en la Guayana Francesa) para recoger las muestras, muchas de ellas nunca antes analizadas ni caracterizadas.
Después de 30 meses de iniciarse el proyecto, 120 especies venenosas han sido recogidas, 30 analizadas por proteómica (estudio a gran escala de las proteínas) y 90 por transcriptómica. Esta es el estudio de la expresión génica en una célula, tejido u órgano; y se basa en la secuenciación y el análisis de las moléculas de ARN.
La empresa española Sistemas Genómicos ha ideado el concepto de transcriptómica de novo, una metodología que permite el análisis de identificación y expresión de moléculas de ARN de interés o transcritos (como toxinas), sin ningún tipo de conocimiento previo sobre el organismo.
“Esta potente aplicación permite la identificación de moléculas desconocidas que no se había explorado antes, abriendo enormes posibilidades para el descubrimiento de nuevos medicamentos”, afirma Rebeca Miñambres, responsable del área de Transcriptómica del proyecto.
Los investigadores usan también nuevas tecnologías de secuenciación masiva (next generation sequencing o NGS), que permiten obtener millones de secuencias que posteriormente son ensambladas a través de procesos bioinformáticos.
“Esperamos obtener un banco de 20.000 secuencias al final del proyecto, que representará la mayor base de datos de secuencia de la toxina que se haya construido hasta el momento”, indica Gilles.
video_iframe
A juicio de este experto, “el proyecto tendrá un impacto importante en la salud pública, ofreciendo tanto la posibilidad de desarrollar fármacos innovadores dirigidos a receptores diana así como nuevas vías terapéuticas para una serie de necesidades médicas no cubiertas actuales”. Según los investigadores, el descubrimiento de cientos de proteínas y sus componentes, los péptidos, en el veneno de una sola especie venenosa abre múltiples posibilidades de investigación farmacológica.
Venomics está financiado con fondos europeos. Cuenta con un presupuesto de 9,1 millones de euros de los cuales 6 millones son subvencionados a través del séptimo programa marco (2011-2015). Empresas de cinco países europeos (Bélgica, Dinamarca, Francia, Portugal y España) participan en esta iniciativa.
- La fuentes de estudio. La CEA (French Alternative Energies and Atomic Energy Commission) adquiere muestras de animales venenosos grandes y pequeños, así como recoge muestras en los territorios franceses (como las islas Mayotte y Tahití).
- La base de datos de secuenciación. El análisis proteómico de los venenos es realizado por la Universidad de Lieja (Bélgica), mientras que el análisis transcriptómico de las glándulas de veneno se lleva a cabo en Sistemas Genomicos (Valencia, España). Gracias a estas evaluaciones, se está proporcionando información complementaria que combinan entre sí (CEA, Francia), generando la lista de toxinas presentes en cada veneno.
- El banco de péptidos. Las toxinas seleccionadas de la base de datos de secuenciación son fabricadas por medio de expresión recombinante (NZYTech -Portugal- y la Universidad de Marsella –Francia-) y química de péptidos (CEA, Francia).
- Creación de nuevos fármacos. La información acumulada en el banco de péptidos finalmente se dirigirá a dianas terapéuticas relacionadas con necesidades médicas no cubiertas (ZELANDA Pharma, Dinamarca, la Universidad Católica de Lovaina, Bélgica y CEA, Francia).
La inhibición de una proteína clave en la señalización del crecimiento celular bloquea la progresión tumoral en el adenocarcinoma de pulmón. Este hallazgo podría combinarse con otras terapias oncológicas y mejorar su efectividad, según un nuevo estudio en ratones.
Las nuevas células, desarrolladas por un equipo científico español, utilizan un sistema de vectores no virales, lo que podría reducir significativamente los costes de producción y mejorar su accesibilidad para pacientes con este tipo de tumores. La Agencia Española de Medicamentos ha autorizado el desarrollo de un ensayo clínico para el tratamiento de pacientes con linfomas de tipo B.



